举例: var intChan chan int (intChan 用于存放 int 数据) var mapChan chan map[int]string (mapChan 用于存放 map[int]string 类型) var perChan chan Person var perChan2 chan *Person ...
说明
channel 是引用类型 ,channel 必须初始化才能写入数据, 即 make 后才能使用 ,管道是有类型的,intChan 只能写入 整数 int
func main() { intChan := make(chan int, 10) for i := 1; i <= 10; i++ { intChan <- i }
stringChan := make(chan string, 100) for i := 6; i <= 16; i++ { stringChan <- "12345" + fmt.Sprintf("%d", i) }
//传统方法遍历管道时会报错 // for v := range intChan { // fmt.Printf("intchan=%v\n", v) // }
// for v := range stringChan { // fmt.Printf("stringchan=%v\n", v) // }
//使用select能避免这个问题 for { select { case v := <-intChan: fmt.Printf("intchan=%d\n", v) time.Sleep(time.Second) case v := <-stringChan: fmt.Printf("stringchan=%s\n", v) time.Sleep(time.Second) default: fmt.Println("读取完毕!!!")
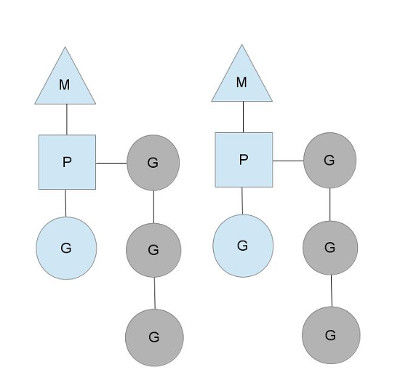
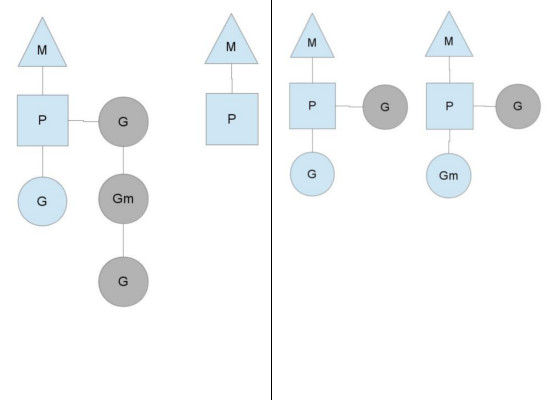
从上图中看,有2个物理线程M,每一个M都拥有一个处理器P,每一个也都有一个正在运行的goroutine。P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
func main() { var monkey = LittleMonkey{Monkey{Name: "wukong"}} var f Fish = &monkey var b Bird = &monkey //LittleMonkey是指针类型,这里需要取地址 monkey.slimbing() f.Swimming() b.Flying() }
对上面代码的小结
当 A 结构体继承了 B 结构体,那么 A 结构就自动的继承了 B 结构体的字段和方法,并且可以直接使用
当 A 结构体需要扩展功能,同时不希望去破坏继承关系,则可以去实现某个接口即可,因此我们可以认为:实现接口是对继承机制的补充.
接口和继承解决的解决的问题不同
1、继承的价值主要在于:解决代码的复用性和可维护性。
2、接口的价值主要在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法。
3、接口比继承更加灵活
接口比继承更加灵活,继承是满足 is - a 的关系,而接口只需满足 like - a 的关系。
4、接口在一定程度上实现代码解耦
接口体现多态
多态参数
在前面的 Usb 接口案例,Usb usb ,即可以接收手机变量,又可以接收相机变量,就体现了 Usb 接口多态。
func main() { var x interface{} var b float64 = 2.333 x = b if y, ok := x.(float32); ok { fmt.Printf("y的类型是%T 值为%v\n", y, y) } else { fmt.Println("error") } fmt.Println("helloworld") }
类型断言的最佳实践 1
在前面的 Usb 接口案例做改进:给 Phone 结构体增加一个特有的方法 call(), 当 Usb 接口接收的是 Phone 变量时,还需要调用 call方法
func (m Monster) jisun() { sum := 0 for i := 1; i <= 1000; i++ { sum += i } fmt.Println(m.Name, "结果是=", sum) } func main() { var N Monster N.Name = "hello" N.jisun() }
func (m Monster) jisun(n int) { sum := 0 for i := 1; i <= n; i++ { sum += i } fmt.Println(m.Name, "结果是=", sum) } func main() { var N Monster N.Name = "hello" N.jisun(100) }
给 Monster结构体添加 getSum 方法,可以计算两个数的和,并返回结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
package main
import ( "fmt" )
type Monster struct { Name string }
func (m Monster) getSum(n1 int, n2 int) (n int) { return n1 + n2 } func main() { var N Monster N.Name = "hello" sum := N.getSum(1, 2) fmt.Println(sum) }
map 声明的举例: var a map[string]string var a map[string]int var a map[int]string var a map[string]map[string]string 注意:声明是不会分配内存的,初始化需要 make ,分配内存后才能赋值和使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
package main
import ( "fmt" )
func main() {
var a map[string]string //在使用map前,需要先make,make的作用就是给map分配可用空间 a = make(map[string]string) a["num1"] = "h" a["num2"] = "e" a["num1"] = "k" fmt.Println(a) }
对上面代码的说明
map 在使用前一定要 make
map 的 key 是不能重复,如果重复了,则以最后这个 key-value 为准
map 的 value 是可以相同的.
map 的 key-value 是无序
make 内置函数数目
1 2 3 4 5 6 7 8 9 10
func make func make(Type, size IntegerType) Type make 内建函数分配并初始化一个类型为切片、映射、或(仅仅为)信道的对象。 与 new 相同的是,其第一个实参为类型,而非值。不同的是,make 的返回类型 与其参数相同,而非指向它的指针。其具体结果取决于具体的类型: